您现在的位置是:首页 > 高性能编程高性能编程
linux syscall耗时分析
![]() 比目鱼2022-01-06【高性能编程】人已围观
比目鱼2022-01-06【高性能编程】人已围观
简介main_syscall.c#include <stdio.h>#include <stdlib.h>#include <ctype.h>#include <unistd.h>#include <sys/types.h>#include "common.h"#define LOOPCNT 20#define BLOCK
每个cpu的core在执行指令(代码)的时候,身边有约30大悍将(寄存器)在辅做,比如最典型的EBP、ESP,当要发生运行空间切换(syscall、中断),这30个寄存器里的数据是不是都要存起来以待再切回来时恢复继续接着干;
几个问题:
什么时候存?
谁存?
存在哪?
什么时候恢复?
最主要这个过程耗时多久?本文syscal揭开耗时的面纱。
程序的大致要干的事;
对64MB 循环访问一把;
连续20次调用同一个syscall函数,并分别记录每次的耗时;
printf 20次的耗时;
循环以上三步骤;
main_syscall.c
#include <stdio.h>
#include <stdlib.h>
#include <ctype.h>
#include <unistd.h>
#include <sys/types.h>
#include "common.h"
#define LOOPCNT 20
#define BLOCKLEN 1000000
int g_aiData[BLOCKLEN][16];
int main(int argc, char ** argv)
{
int i;
long long t1, t2;
struct timespec stTP;
long long aldiff[LOOPCNT] = { 0 };
int iTemp = 0;
while(1)
{
for (i = 0; i < BLOCKLEN; i++) /* 64MB的内存先访问一把,把L1 L2 L3尽力刷一把 */
g_aiData[i][0] = i;
aldiff[0] = 0;
for (i = 0; i < LOOPCNT; i++)
{
t1 = rte_rdtsc(); /* 直接从rdtsc寄存器取,注:这个是x86_64上的 */
getnstime(&stTP); /* 这个函数会走syscall进内核 */
t2 = rte_rdtsc();
aldiff[i] = t2 - t1;
}
printf("----------------------------\n");
for (i = 0; i < LOOPCNT; i++)
{
printf("%d:%lld, ", i, aldiff[i]);
}
printf("\n");
}
return 0;
}common.c
#include <sys/time.h>
#include <time.h>
#include <stdlib.h>
#include <stdio.h>
#include "common.h"
//typedef unsigned long long uint64_t;
long long getustime(void)
{
struct timeval tv;
long long ust;
gettimeofday(&tv, NULL);
ust = ((long)tv.tv_sec)*1000000;
ust += tv.tv_usec;
return ust;
}
void getnstime(struct timespec *pstTP)
{
clock_gettime(CLOCK_MONOTONIC_RAW, pstTP); /* 这里带RAW的是会syscall进内核的 */
return;
}
long diff_nstime(struct timespec *pstTP1, struct timespec *pstTP2)
{
return (pstTP2->tv_sec - pstTP1->tv_sec)*1000000000 + pstTP2->tv_nsec - pstTP1->tv_nsec;
}
inline long long rte_rdtsc(void)
{
union {
long long tsc_64;
struct {
unsigned int lo_32;
unsigned int hi_32;
};
} tsc;
asm volatile("rdtsc" :
"=a" (tsc.lo_32),
"=d" (tsc.hi_32));
return tsc.tsc_64;
}common.h
#ifndef COMMON_H_ #define COMMON_H_ #define ERROR_SUCCESS 0 #define ERROR_FAIL 1 #define IN #define OUT #define INOUT #define CACHE_LINE 64 //#define HASHSIZE 1*1024 typedef unsigned long ulong_t; long long getustime(void); void getnstime(struct timespec *pstTP); long diff_nstime(struct timespec *pstTP1, struct timespec *pstTP2); inline long long rte_rdtsc(void); #endif

可以看出,每轮都是第1次耗时最长,约3000(计时单位是时钟周期)这个量级,后面接着的都是300,相差了近10倍;
为什么会是这样?
我们平常调的系统调用都是每轮第1次这个样子么?
Tags:
很赞哦! ()
下一篇:服务器主板北桥南桥的发展
随机图文
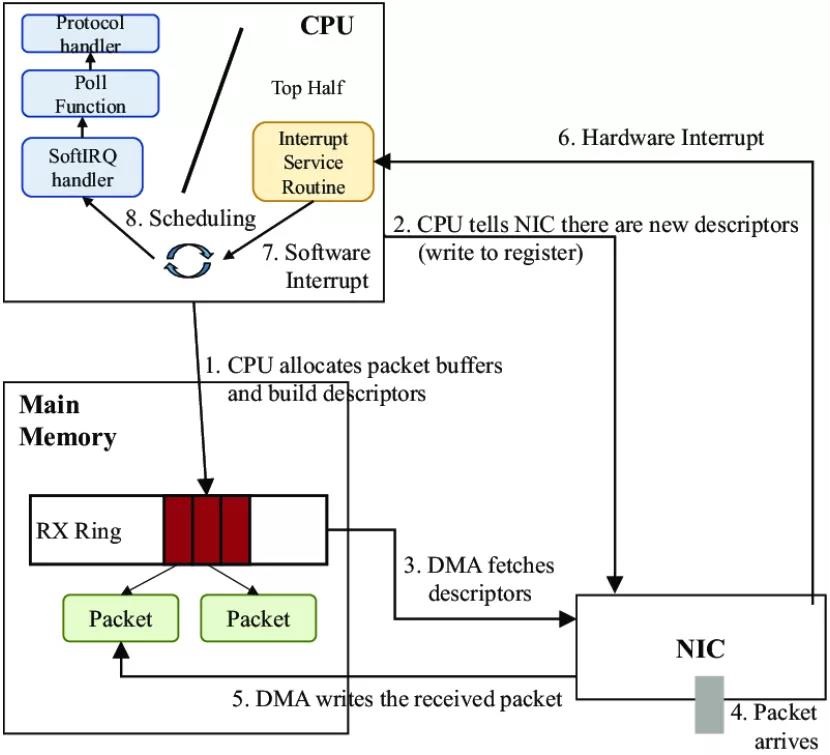
linux中报文从网卡到用户态recv的架子
分享一篇后台服务器性能优化之网络性能优化,希望大家对Linux网络有更深的理解。曾几何时,一切都是那么简单。网卡很慢,只有一个队列。当数据包到达时,网卡通过DMA复制数据包并发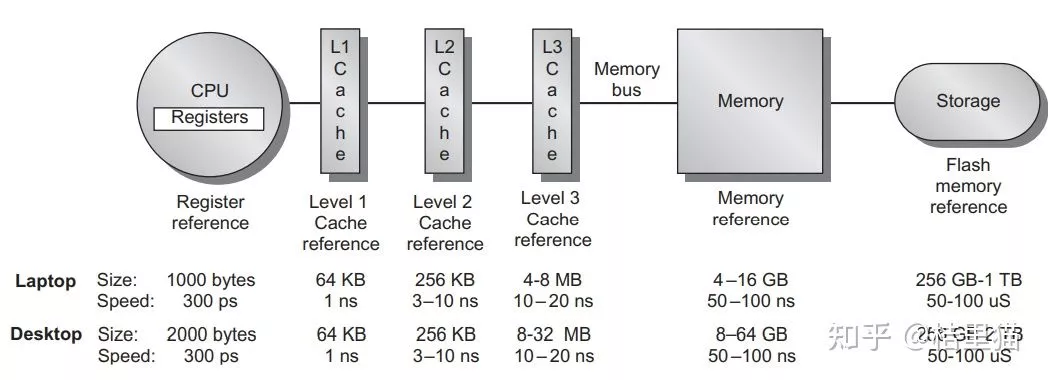
深入理解 Cache 工作原理
大家好,今天给大家分享一篇关于 Cache 的硬核的技术文,基本上关于Cache的所有知识点都可以在这篇文章里看到。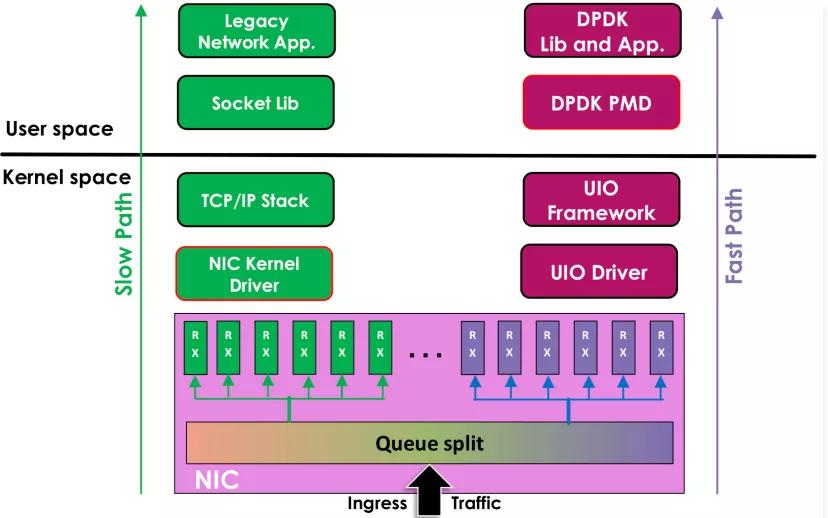
深入理解DPDK程序设计|Linux网络2.0
移动互联网不断发展,网络流量徒增,推动着网络技术不断地发展,而CPU的运行频率基本停留在10年前的水平,为了迎接超高速网络技术的挑战,软件也需要大幅度创新,结合硬件技术的发展,DPDK,一个以软件优化为主的数据面技术应时而生,它为今天NFV技术的发展提供了绝佳的平台可行性。 作为技术人员,我们可以从中DPDK学习大量的高性能编程技巧和代码优化技巧,包括高性能软件架构最佳实践、高效数据结构设计和内存优化技巧、应用程序性能分析以及网络性能优化的技巧。
文章评论
本站推荐

猜你喜欢

