您现在的位置是:首页 > Linux OSLinux OS
深入理解Linux自旋锁---程磊篇
![]() 转载2022-08-08【Linux OS】人已围观
转载2022-08-08【Linux OS】人已围观
简介作者简介:
程磊,一线码农,在某手机公司担任系统开发工程师,日常喜欢研究内核基本原理。
目录
一、自旋锁的发展历史
二、原始自旋锁
三、票号自旋锁
四、MCS自旋锁
五、队列自旋锁
六、自旋锁的使用
一、自旋锁的发展历史
自旋锁是Linux内核里最常用的锁之一,自旋锁的概念很简单,就是如果加锁失败在等锁时是使用休眠等待还是忙等待,如果是忙等待的话,就是自旋锁,这也是自旋锁名字的由来。自旋锁的逻辑是,用自旋锁保护的临界区要足够小,而且临界区内是不能休眠的。所以当自旋锁加锁失败时,说明有其它的临界区正在执行中。由于自旋锁的临界区足够小且不会休眠,所以我们可以自旋忙等待其它临界区的退出,没必要去休眠,因为休眠要做一大堆操作。而忙等待的话,对方很快就会退出临界区,我们就可以很快地获得自旋锁了。
自旋锁与UP、SMP的关系:
根据自旋锁的逻辑,自旋锁的临界区是不能休眠的。在UP下,只有一个CPU,如果我们执行到了临界区,此时自旋锁是不可能处于加锁状态的。因为我们正在占用CPU,又没有其它的CPU,其它的临界区要么没有到来、要么已经执行过去了。所以我们是一定能获得自旋锁的,所以自旋锁对UP来说是没有意义的。但是为了在UP和SMP下代码的一致性,UP下也有自旋锁,但是自旋锁的定义就变成了空结构体,自旋锁的加锁操作就退化成了禁用抢占,自旋锁的解锁操作也就退化成了开启抢占。所以说自旋锁只适用于SMP,但是在UP下也提供了兼容操作。
自旋锁一开始的实现是很简单的,后来随着众核时代的到来,自旋锁的公平性成了很大的问题,于是内核实现了票号自旋锁(ticket spinlock)来保证加锁的公平性。后来又发现票号自旋锁有很大的性能问题,于是又开始着力解决自旋锁的性能问题。先是开发出了MCS自旋锁,确实解决了性能问题,但是它改变了自旋锁的接口,所以没办法替代自旋锁。然后又有人对MCS自旋锁进行改造从而开发出了队列自旋锁(queue spinlock)。队列自旋锁既解决了自旋锁的性能问题,又保持了自旋锁的原有接口,非常完美。现在内核使用的自旋锁是队列自旋锁。下面我们用一张图来总结一下自旋锁的发展史(x86平台)。
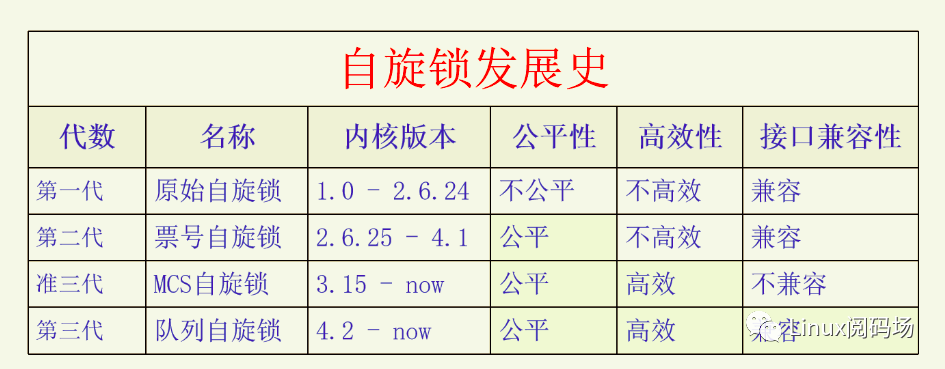
注:MCS自旋锁进了内核,但是由于接口不兼容和体积问题,并没有取代票号自旋锁。
下面我们将按照自旋锁的发展顺序来逐步讲解,本文的代码都是按照x86平台进行讲解的,代码都进行了删减,把一些调试数据或者无关紧要的数据、代码都删除了。
二、原始自旋锁
我们在《深入理解Linux线程同步》里面讲了简单自旋锁,原始自旋锁和它的原理是一样的,但是实现细节更为复杂一些。本节以内核版本2.6.24来讲解代码。
2.1 定义与初始化
我们先来看原始自旋锁的定义。
linux-src/include/linux/spinlock_types.h
做了删减,把调试相关的配置数据都删了。
linux-src/include/asm-x86/spinlock_types.h
我们可以看到原始自旋锁的定义非常简单,本质上就是一个无符号整数。
下面我们再来看一下自旋锁变量的定义与初始化。自旋锁的定义与初始化分为静态和动态两种。静态是指自旋锁在编译时就分配好了空间、数据就初始化好了,这种情况一般是全局自旋锁变量。动态是指自旋锁是在运行时去创建然后用函数去初始化的,这种情况一般是自旋锁内嵌在某个结构体里面,随着结构体的创建而创建,需要用函数去初始化一下。
静态定义与初始化如下:
linux-src/include/linux/spinlock_types.h
linux-src/include/asm-x86/spinlock_types.h
自旋锁的动态初始化如下:
linux-src/include/linux/spinlock.h
此处的do while(0)是为了能把宏当做函数一样来用。我们调用函数时最后面都要加个;分号,如果没有do while(0),我们在最后加个;分号,语法就不对了,如果不加,宏看上去就不像是函数调用了。有了do while(0),这个问题就解决了。
静态初始化是在编译时就对变量赋值了,动态初始化是在运行时才对变量进行赋值。
2.2 加锁操作
下面我们来看一下自旋锁的加锁操作:
linux-src/include/linux/spinlock.h
linux-src/kernel/spinlock.c
linux-src/include/linux/lockdep.h
linux-src/include/linux/spinlock.h
linux-src/include/asm-x86/spinlock_32.h
linux-src/include/asm-x86/spinlock_64.h
可以看到spin_lock的最终实现是__raw_spin_lock,是在架构代码里面,在x86上分为32位和64位两种实现,用的都是内嵌汇编代码。关于内嵌汇编,可以查询gcc的官方文档GCC内嵌汇编语言。
这两段内嵌汇编代码的意思都是一样的,但是比较晦涩难懂,我们把它转换为C代码。
转换成C代码之后就很好理解了。原始自旋锁用1来表示没有加锁,在无限循环中,我们首先把锁变量原子地减1并比较是否等于0,如果等于0,说明刚才锁变量是1,现在变成了0,我们加锁成功了,直接返回。如果锁变量不等于0,就是说锁变量刚才是0,现在变成负的了,那么我们就无限循环锁变量小于等于0,直到锁变量大于0,也就是等于1,结束此循环,重新回到大循环中去尝试加锁。为什么要把锁变量强转为int呢,因为锁变量的定义是无符号数,而在汇编代码中把它当做有符号数使用,所以加个int强转。为什么内循环是小于等于0而不是小于0呢,首先刚到达内循环的时候,说明我们抢锁失败,锁变量一定是小于0的,在内循环执行的过程中,如果有人释放了锁而又有人立马抢到了锁,此时锁变量还是0,此时我们结束内循环去抢锁是没有意义的,抢锁肯定会失败还会回到内循环。所以只有当锁变量大于0也就是等于1时,代表锁是空闲的,此时结束内循环才是有意义的。
2.3 解锁操作
下面我们看一下解锁操作:
linux-src/include/linux/spinlock.h
linux-src/kernel/spinlock.c
linux-src/include/linux/spinlock.h
linux-src/include/asm-x86/spinlock_32.h
linux-src/include/asm-x86/spinlock_64.h
可以看到解锁操作也是在架构代码里面实现的,用的也是内嵌汇编代码,这个代码比较简单,就是把锁变量赋值为1,我们就不再转换成C代码了。
三、票号自旋锁
看了上面的原始自旋锁实现之后,我们发现自旋锁并没有排队机制,如果有很多人在竞争锁的情况下,谁能获得锁是不确定的。在CPU核数还比较少的时候,这个问题并不突出,内核也没有去解决这个问题。后来随着CPU核数越来越多,内核越来越复杂、锁竞争越来越激烈,自旋锁的不公平性问题就越来越突出了。有人做了个实验,在一个8核CPU的电脑上,有的线程竟然连续100万次都没有获得自旋锁。这个不公平性就太严重了,解决自旋锁的公平性问题就迫在眉睫了。
为了解决自旋锁的公平性问题,内核开发了票号自旋锁。它的原理就类似于我们去银行办业务,以前没有叫号机,我们每个人都盯着业务窗口看,发现一个人走了立马一窝蜂地挤过去,谁抢到了位置就轮到谁办业务。在人特别多的时候,有的人可能早上十点来的,下午五点都没抢到机会。这怎么能行呢,太不公平了,于是银行买了叫号机,每个进来的人都先取一个号,然后坐着等。业务员处理完一个人的业务之后就播报下一个要处理的票号。每个人都要一直注意着广播播报,发现广播里叫的号和自己手里的号是一样的,就轮到自己去办业务了。
票号自旋锁在实现时把原来的自旋锁的整形变量拆分成了两部分,一部分是owner,代表当前正在办业务的票号,另一部分是next,代表下一个人取号的号码。每次加锁时先取号,定义一个局部变量int ticket = next++,自己取的号是next的值,再把next的值加1,然后不停地比较自己的ticket和owner的值,如果不相等就一直比较,直到相等为止,相等代表加锁成功,该自己去办业务了。办业务就相当于临界区,办完业务离开临界区,解锁自旋锁就是把owner加1。此时如果有其它人在自旋,他发现owner加1之后和自己的ticket相等了,就结束自旋,代表他加锁成功了。我们来画一个图来演示一下:
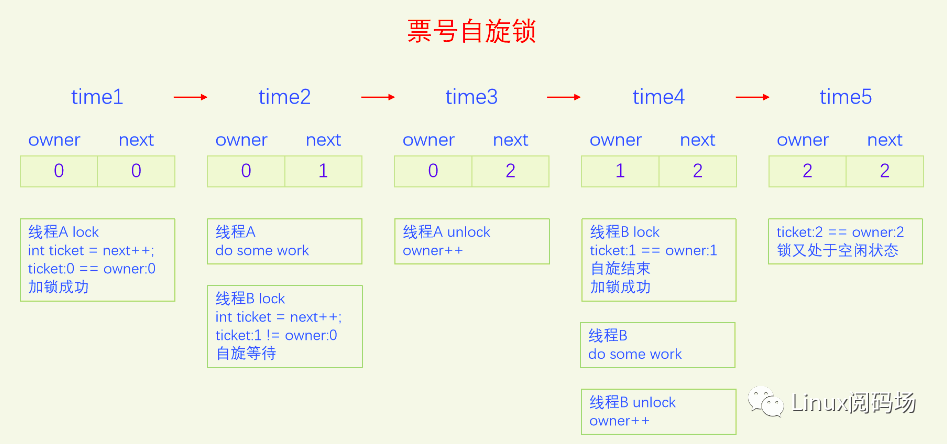
票号自旋锁的状态和原始自旋锁有很大不同,原始自旋锁是1代表未加锁,0代表已加锁,看不出来排队等锁的线程有多少个。票号自旋锁,owner和next相等代表未加锁,两者不一定等于0,next和owner的差值等于排队等锁的线程个数。
下面我们以内核版本4.1来讲解。在x86的实现上,owner叫head,next叫tail,其实这么叫也很合理,从head到tail正好是所有加锁的人构成的一个队列,head是队首,已经获得了锁,tail是队尾,是下一个来的人的序号。
3.1 定义与初始化
我们先来看票号自旋锁的定义:
linux-src/include/linux/spinlock_types.h
linux-src/arch/x86/include/asm/spinlock_types.h
这里同样把一些调试数据代码进行了删除。spinlock包含raw_spinlock,raw_spinlock包含arch_spinlock_t,之前只有两层,spinlock是对外接口,raw_spinlock是各个架构的实现,现在为什么又多了个arch_spinlock_t呢,原因和RTLinux有关。为了配合RTLinux的实现,Linus决定把原来的raw_spinlock改为arch_spinlock,把原来的spinlock改为raw_spinlock,再实现一个新的spinlock来包含raw_spinlock。这样的话,arch_spinlock就是各个架构的实现,spinlock和raw_spinlock在标准Linux下的含义没有区别,在RTLinux下含义不同,具体请看6.3节的讲解。
arch_spinlock中使用了共用体,既可以把head tail当成一个变量来处理,又可以把它们分开当成两个变量来处理。
下面我们来看一下票号自旋锁的初始化。
静态初始化如下:
linux-src/include/linux/spinlock_types.h
linux-src/arch/x86/include/asm/spinlock_types.h
动态初始化如下:
linux-src/include/linux/spinlock.h
linux-src/include/linux/spinlock_types.h
静态初始化和动态初始化都把票号自旋锁初始化为{head:0,tail:0}状态,head和tail相同表明锁当前是未加锁状态。
3.2 加锁操作
下面我们来看一下票号自旋锁的加锁操作:
linux-src/include/linux/spinlock.h
linux-src/kernel/locking/spinlock.c
linux-src/include/linux/spinlock_api_smp.h
inux-src/include/linux/lockdep.h
linux-src/include/linux/spinlock.h
linux-src/arch/x86/include/asm/spinlock.h
通过层层调用,spin_lock最终调用架构下的函数arch_spin_lock。arch_spin_lock函数和我们前面讲的逻辑是一样的,只不过是代码实现需要稍微解释一下。首先定义了一个局部变量inc,inc的初始值是tail为1,然后通过xadd函数把自旋锁的tail加1,并返回原自旋锁的值,xadd函数是原子操作,此时得到的inc的tail值就是我们的票号ticket。先判断一下我们的ticket(inc.tail)是否和owner(inc.head)相等,如果相等代表我们加锁成功了,goto out。如果不相等,就进入一个无限for循环,不停地读取lock->tickets.head的值,和自己的ticket比较,如果不相等就一直比较,如果相等则代表我们加锁成功了,退出循环。为了避免其它代码有问题而产生死锁,上述操作是在for循环里面又加了个do while循环,只循环一定的次数。
3.3 解锁操作
下面我们看一下票号自旋锁的解锁操作:
linux-src/include/linux/spinlock.h
linux-src/kernel/locking/spinlock.c
linux-src/include/linux/spinlock_api_smp.h
linux-src/include/linux/spinlock.h
linux-src/arch/x86/include/asm/spinlock.h
解锁操作还是挺简单的,最终只是把head也就是owner加1了而已。
四、MCS自旋锁
上面的票号自旋锁完美地解决了公平问题,逻辑简单,代码简洁。但是还存在着一个严重的问题,就是当锁竞争比较激烈的时候,大家都在自旋head变量,会导致缓存颠簸,严重降低了CPU的性能。为了解决这个问题,我们应当设计出一种锁,把所有排队等锁的线程放到一个队列上,每个线程都自旋自己的节点,这样就不会有缓存颠簸问题了,而且还是公平锁。MCS锁就是这么设计的,锁本身是个指针,指向排队队列的末尾,每个申请加锁的线程都要自己创建一个锁节点,然后把自己放到这个队列的末尾并让锁指针指向自己,最后在自己的节点上自旋。当线程解锁时,要看看自己的next指针是否为空,如果不为空说明有人在等锁,要把next节点设置为加锁状态,这样下一个线程就获得了自旋锁。下面我们画个图看一下:
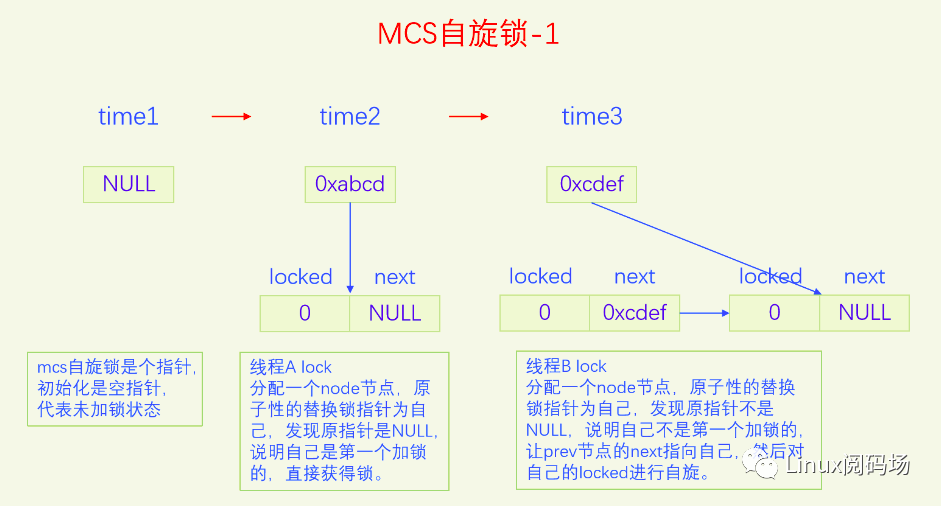
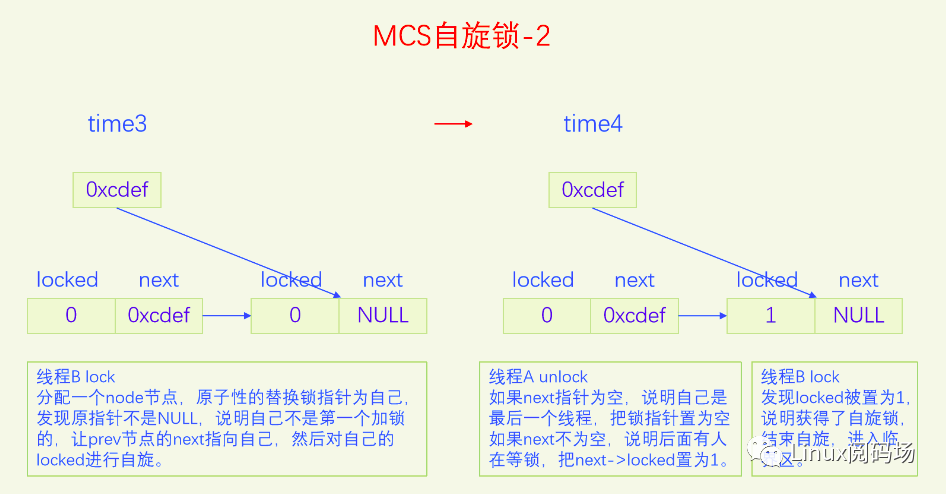
图片演示了MCS自旋锁基本的加锁解锁操作,但是有一个细节情况没有考虑,这点在代码里会进行分析。
下面我们用内核版本4.1来讲解。
4.1 定义与初始化
我们先来看一下MCS自旋锁的定义:
linux-src/kernel/locking/mcs_spinlock.h
这个定义非常简单,没有复杂的嵌套定义。要注意的是MCS锁本身是 struct mcs_spinlock *,是个指针,而结构体struct mcs_spinlock本身并不是锁,而是加锁时的排队节点,我们把它叫做锁节点,这是MCS锁与大部分锁不同的地方,大部分锁都只有一个锁变量,不需要加锁线程再去分配锁节点,而MCS锁需要加锁线程去分配一个锁节点。
MCS自旋锁没有特定的初始化,就是定义一个空指针而已。
Lock为空指针代表锁处于空闲状态。
4.2 加锁操作
下面我们来看一下MCS自旋锁的加锁操作:
linux-src/kernel/locking/mcs_spinlock.h
原子地交换锁变量的原值和本线程锁节点的地址值并返回锁变量的原值保存到prev变量。如果prev的值是空指针,代表锁变量之前是空闲状态,我们是第一个加锁的,直接获得了锁,直接return。如果prev不为NULL,说明有人已经获得了锁,我们只能等待,让prev的next指针指向自己,然后在自己的locked上自旋。
4.3 解锁操作
下面我们看一下解锁操作:
linux-src/kernel/locking/mcs_spinlock.h
先读出自己的next指针,如果为空指针,说明我们是最后一个线程,可以直接返回了。但是在返回前要把锁变量设为空指针,代表锁现在是空闲状态。但是这里并不是直接设置,而是使用原子交换CAS,只有当锁变量指向自己的时候才把锁变量置为空,这么做是为了避免和加锁操作发生冲突。如果操作成功,代表释放锁成功,直接return。如果操作失败,说明有线程在同时执行加锁操作,它会把我们的next指针设置为指向它,然后在它的locked上自旋,所以我们要等我们的next被设置之后也就是不为空的时候,再把next->locked设置为1。如果一开始我们的next指针就不为空,那么直接把next->locked设置为1就行了。下一个线程发现自己的locked为1就会结束自旋,从而获得了锁。
五、队列自旋锁
MCS锁有一个很大的问题就是它改变了自旋锁的接口,这是一个很严重的问题,内核里使用自旋锁的地方很多,如果把自旋锁都改为MCS自旋锁,那将是非常麻烦的。同时MCS还有一个问题就是它的体积增大了,这也是一个很严重的问题。为了解决MCS自旋锁的问题,内核又开发了队列自旋锁。它结合了MCS锁的优点,但是又做了很大的改进,同时又优化了锁竞争比较少的场景。队列自旋锁对MCS自旋锁的优化原理是,一个系统最多同时有NR_CPU个自旋锁在运行,所以没必要每个加锁线程都自己分配一个锁节点,我们在系统全局预分配NR_CPU个锁节点就可以了,哪个CPU上要执行自旋锁,就去用对应的锁节点就可以了。这是对于只有线程的情况,实际上还有软中断、硬中断、NMI,它们后者都可以抢占前者,都能抢占线程,所以整个系统实际上总共需要NR_CPU * 4 个锁节点就足够了。队列自旋锁还对只有两个线程去抢锁的情况作了优化,这种情况下不会使用MCS的排队逻辑。
下面我们用一个比喻来说一下队列自旋锁的总体逻辑。我们把锁的位置比作皇位,抢到皇位就是加锁成功就可以进入临界区了。第一个来抢锁的人就是直接抢锁成功,抢到皇位。第二个来抢锁的人发现皇位已经被抢了,退而求其次,抢占太子位,然后一直自旋皇位,一旦皇帝驾崩让出皇位,自己就立马抢占皇位。第三个来抢锁的人发现皇位和太子位都被抢了,没有办法只能去抢太孙的位置,然后同时自旋太子位和皇位。当皇位空缺的时候,太子会替补到皇位,此时太子位空缺,但是太孙并不会去抢占太子位,他还待在太孙位上,直到太子位和皇位同时空缺了,他才会一步到位,直接从太孙位上登基为皇帝。第四个人来了发现皇位、太子位、太孙位都被抢了,就只能占个皇孙位了,从第四个人开始包括后面来的每个人都是皇孙,所有皇孙依次排好队等待进位成太孙。太孙其实也算是皇孙,太孙是第一皇孙,其它的都是普通皇孙。皇孙也在自旋,只不过皇孙是在自己家门口自旋,他一直在等待上一任太孙到自己家门口叫自己。太孙发现皇位和太子位同时空缺了之后就会去继承皇帝位,同时去通知第二皇孙,太孙位空出来了,你可以来当太孙了。然后第二皇孙就变成太孙了,变成太孙之后他也是去同时自旋太子位和皇位。当他也登基称帝之后他也会去通知后面的第二皇孙来进位太孙位。然后就一直继续这样的逻辑,后面来的每个人只要发现有太孙存在就只能去占个皇孙位来排队,然后在自己家门口自旋。在这个过程中太子位是一直空缺的。除非最后一个太孙登基称帝之后发现没有皇孙了,此时就没有人进位成太孙了,如果此时再来了人抢位子,而皇位还被占着,他才会去抢太子位。
前面说的逻辑比较复杂,我们再来总结一下,当只有两个人抢锁时,一个占据皇帝位也就是抢锁成功,一个人占据太子位,同时自旋皇位。也就是说同时抢锁的人小于等于两人时不会使用排队机制。第三人来抢锁的话就会启动排队机制,他排在队列的第一位,是第一皇孙,也叫太孙,之后来的人都是普通皇孙,要依次排队。皇孙都是在自己家门口自旋自己,等待前太孙来通知自己进位为太孙。太孙的逻辑是最为复杂的,他要同时自旋太子位和皇位,只有当太子位和皇位都空缺时,太孙才会一步到位登基称帝,然后通知第二皇孙进位为太孙。解锁的逻辑很简单,只需要把皇位设为0就可以了,什么都不用管,因为太子、太孙他们自己会自旋皇位。
队列自旋锁的实现是把原先的锁变量int分为三部分,一个locked字节,对应我们所说的皇位,一个pending字节,对应我们所说的太子位,一个tail双字节,它指向皇孙队列的末尾,皇孙队列的队首是太孙。tail不是个指针,而是逻辑指针,它是通过编码的方式指向队尾皇孙的。每个皇孙都对应一个锁节点,系统预先分配了NR_CPU * 4个锁节点,NR_CPU代表1个CPU 1个,为什么乘以4呢,因为1个CPU上最多可以同时嵌套4个执行流,分别是线程、软中断、硬中断、非屏蔽中断。tail有16位,分两部分编码,其中2位用来编码是哪个执行流,14位用来编码CPU index。CPU编码时要加1,因为CPU index从0开始,而tail等于0有特殊含义,代表的是空指针,也就是没有皇孙来竞争,所以要加上1做区分。当一个线程(执行流)来争锁时,如果太子位被抢了或者已经有太孙了,自己就需要加入皇孙队列,加入皇孙队列的方法就是根据自己所在的CPU index 和自己的执行流等级去拿一个锁节点,把这个锁节点加入到队列中去,并自旋这个锁节点。
下面我们画图来看一下。
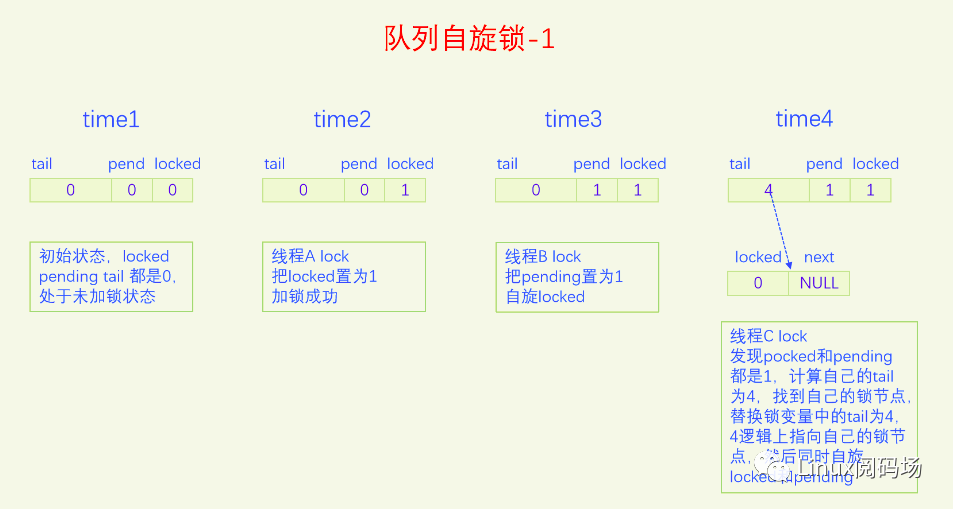
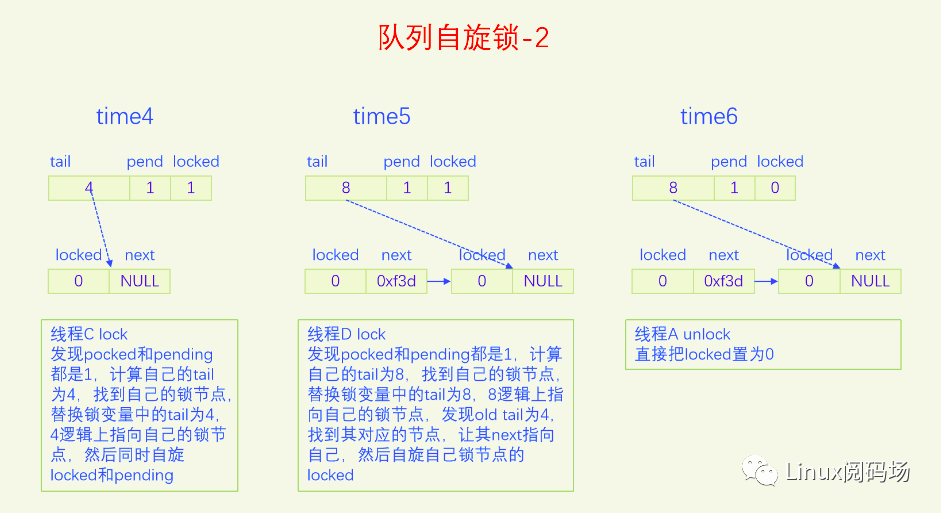
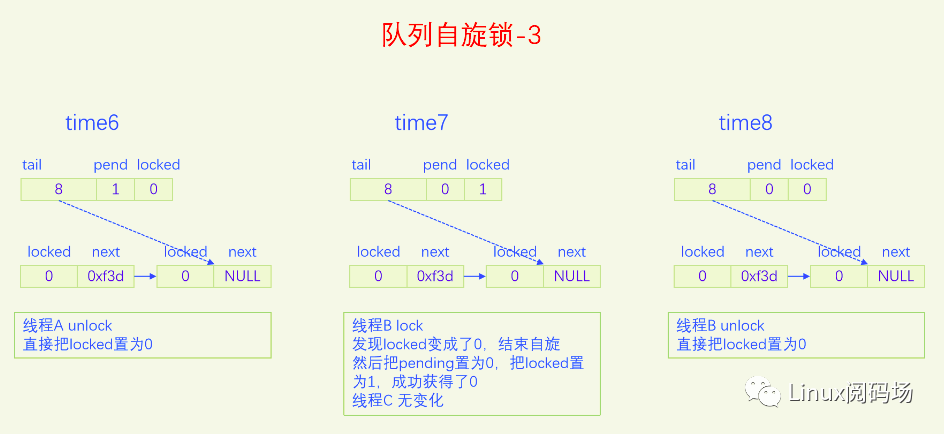
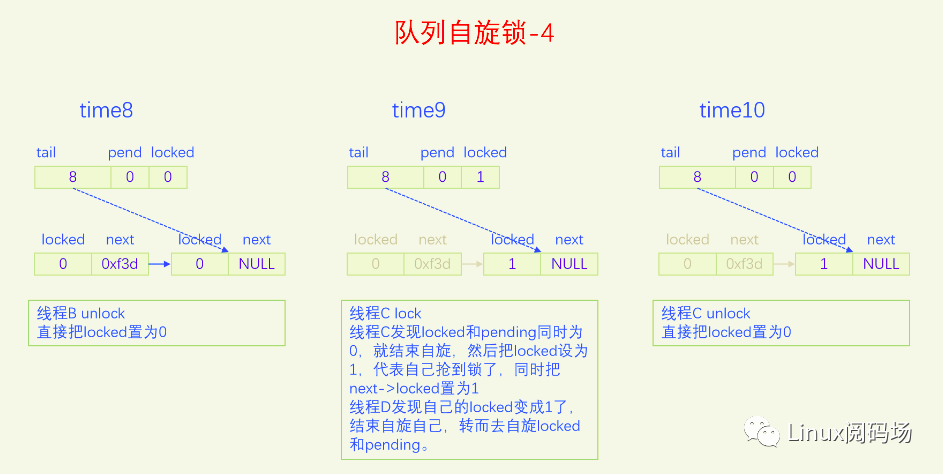
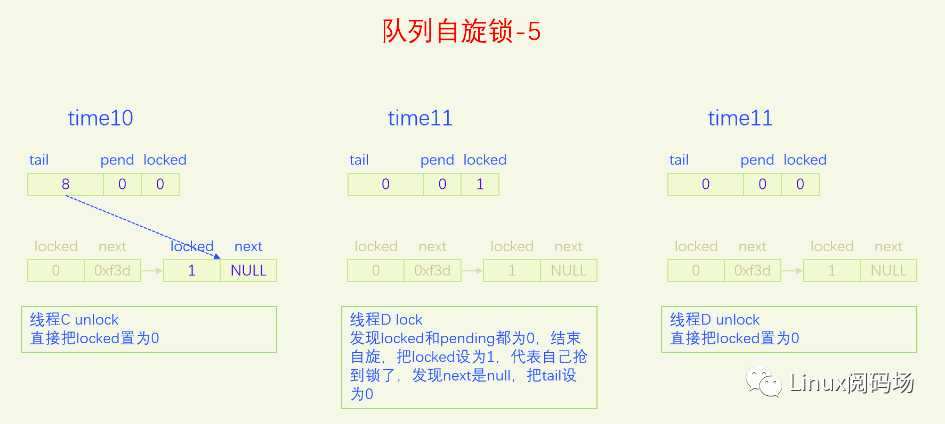
现在大家应该对队列自旋锁的逻辑很熟悉了,下面我们以内核版本5.15.28为例,来看一下队列自旋的代码实现。
5.1 定义与初始化
我们先来看一下队列自旋锁的定义:
linux-src/include/linux/spinlock_types.h
linux-src/include/linux/spinlock_types_raw.h
linux-src/include/asm-generic/qspinlock_types.h
可以看出队列自旋锁的定义最终与原始自旋锁和票号自旋锁的大小是一样的。队列自旋锁也使用了共用体的技巧,把一个4字节的int拆分成了1个字节的locked,一个字节的pending,两个字节的tail。
下面我们来看一下初始化,先看静态初始化:
linux-src/include/linux/spinlock_types.h
linux-src/include/asm-generic/qspinlock_types.h
再看动态初始化
linux-src/include/linux/spinlock.h
无论静态初始化还是动态初始化都是把锁变量的整个int初始化为0。
5.2 加锁操作
我们先来看一下锁节点的定义和相关操作:
linux-src/kernel/locking/qspinlock.c
可以看到锁节点用的是MCS自旋锁的锁节点类型,然后定义了一个per CPU变量,每个CPU上有4个节点,代表4层执行流,线程、软中断、硬中断、屏蔽中断。和MCS自旋锁不同的是,MCS自旋锁需要每个线程在申请锁时自己提供锁节点,而队列自旋锁是提前定义好的全局静态变量,每个执行流在申请锁时根据自己所在的CPU index 和执行流层级去使用对应的锁节点,加锁成功后锁节点就默认放回了。使用锁节点时执行个查询操作就可以了,放回锁节点什么也不用做,这是自旋锁的特点所决定的。因为自旋锁是不能休眠的,所以自旋锁的临界区是一口气执行完,不会切走让其它线程也来申请自旋锁,一个CPU上最左嵌套4层执行流,所以整个系统最多能同时有NR_CPU * 4个自旋锁申请。所以系统预定义NR_CPU * 4个锁节点就足够了,用的时候就直接用,用完啥也不用管。
下面我们来看一下锁节点的编码与查找:
linux-src/kernel/locking/qspinlock.c
可以看到知道了CPU index和执行流层级就可以编码出tail,知道了tail就可以解码出CPU index和执行流层级,就可以去全局变量qnodes中找到对应的锁节点。如果已经知道了CPU index对应的锁节点base,再根据执行流层级也可以找到对应的锁节点。
下面我们来看一下队列自旋锁的加锁操作:
linux-src/include/linux/spinlock.h
linux-src/kernel/locking/spinlock.c
linux-src/include/linux/spinlock_api_smp.h
linux-src/include/linux/lockdep.h
linux-src/include/linux/spinlock.h
linux-src/include/asm-generic/qspinlock.h
linux-src/include/asm-generic/qspinlock_types.h
linux-src/kernel/locking/qspinlock.c
加锁的时候要首先看一下是不是锁变量的整个int都是0,如果是的话,说明皇位、太子位、太孙位都是空的,锁现在是空闲的,没有任何人竞争,我们直接把锁变量设为1(用的是原子操作),代表我们抢锁成功,直接返回。如果整个锁变量不为0,说明存在锁竞争,我们要走慢速路径。
在慢速路径里,首先处理的是如果遇到太子正在登基,则自旋等待太子登基成功。然后查看太子位是否被占,如果被占,则goto queue,也就是进入皇孙排队流程(这个后面再讲)。如果太子位没被占,则尝试占领太子位。如果抢占太子失败,说明有其它线程也在抢太子位,我们抢失败了,则我们则goto queue,也就是进入皇孙排队流程(这个后面再讲)。如果抢占太子位成功,则自旋皇帝位,一直自旋到皇帝驾崩把锁置为0,则我们结束自旋,原子地占领皇位释放太子位,然后return。
接下来是皇孙排队逻辑,每一个新来的皇孙都要排到队尾。队尾是用锁变量中的tail来记录的。我们要先生成自己的队尾编码tail,找到自己对应的锁节点。此时再尝试一下加锁操作,因为有可能现在太子太孙皇位都是空的,如果尝试成功就结束流程,如果失败则继续往下走。然后原子地交换锁变量的tail和自己的tail,这样我们就成为新的队尾了。然后我们再看old tail,分两种情况,如果old tail是空,则说明我们是第一个皇孙,也就是太孙,走太孙逻辑,如果old tail不空,则说明我们是普通皇孙,走皇孙排队逻辑。我们先说皇孙排队逻辑。皇孙排队先解码old tail,找到其对应的锁节点prev,然后让prev的next指向自己,这样我们就加入了排队队列。然后我们就在自己家里自旋,也就是自旋自己的node->locked。我们的自旋是在等待prev先成为太孙,然后当他登基称帝之后,他就会来解除我们的自旋,然后我们就成为了太孙。
下面我们讲太孙的逻辑,太孙的来源有两种,一种是上面说的old tail为空,则我们直接就是太孙,是第一位太孙。第二种来源是普通皇孙进位为太孙。不管哪种来源的太孙,操作都是一样的。太孙首先自旋太子位和皇位,当太子位和皇位同时空缺的时候才会结束自旋。结束自旋之后,先看看自己是不是唯一的皇孙,如果是的话则原子地加锁。如果加锁成功则结束流程,如果加锁失败则说明刚才发生了冲突,又有了新的皇孙加入。如果自己不是唯一的皇孙或者又有新的皇孙加入,则自己先抢占皇位,然后通知next皇孙结束自旋,next皇孙就会成为新的太孙,继续执行太孙的流程。
5.3 解锁操作
下面我们看一下队列自旋锁的解锁操作:
linux-src/include/linux/spinlock.h
linux-src/kernel/locking/spinlock.c
linux-src/include/linux/spinlock_api_smp.h
linux-src/include/linux/spinlock.h
linux-src/include/asm-generic/qspinlock.h
linux-src/include/asm-generic/qspinlock.h
可以看到队列自旋锁的解锁确实很简单,只需要让出皇位也就是把locked字节设为0就可以了。
六、自旋锁的使用
前面几节我们讲了自旋锁的发展历史,以及每一代自旋锁的实现原理。现在我们来讲一讲自旋锁的使用问题,包括自旋锁的适用场景、自旋锁与禁用伪并发的配合使用问题,还有spinlock_t、raw_spin_lock该如何选择的问题。
6.1 自旋锁的适用场景
内核里有很多同步措施,我们什么时候应该使用自旋锁呢,使用自旋锁应该注意什么呢?首先自旋锁适用那些临界区比较小的地方,具体要多小呢,并没有绝对的标准,我记的有的书上说要小于1000个指令或者100行代码。其次临界区内不能休眠,也就是不能有阻塞操作,如果临界区内某些函数调用可能会阻塞,那就不能使用自旋锁。使用自旋锁要注意的点也是临界区不能调用阻塞函数。但是很多时候并不太好判断,有些函数明显就是阻塞函数,肯定不能调用。但是有些函数自己不是阻塞的,而它层层调用的函数中有阻塞的,这就不太好发现了。
线程是可调度的,所以线程可以用互斥锁、信号量,也能用自旋锁。但是中断(包括硬中断和软中断)是不可调度的,也就是说,是不能休眠的,所以只能使用自旋锁。
6.2 自旋锁与禁用伪并发的配合使用
内核里有四种不同类型的执行流,线程、软中断、硬中断、NMI中断,前者不能抢占后者,但是后者能抢占前者。自旋锁能防止两个CPU同时进入临界区,但是并不能防止本CPU的临界区被高级的执行流所抢占。所以当两个关联临界区在不同类型的执行流的时候,只使用自旋锁是不够的,低级执行流还得临时禁止高级执行流的抢占才行。由于NMI中断是不可禁止的,而且NMI中断发生的概率非常低,一般我们的代码也不会与NMI中断发生关联,所以NMI中断就不考虑了。现在只剩下线程、软中断、硬中断三种情况了。组合下来有6种情况,我们依依说明。线程对线程,自旋锁内部已经禁用了线程抢占,所以两个线程之间的临界区直接使用自旋锁就可以了。线程对软中断,线程会被软中断抢占,所以线程中要自旋锁加禁用软中断,而软中断不会被线程抢占,所以软中断中只使用自旋锁就可以了。线程对硬中断,线程会被硬中断抢占,所以线程中要自旋锁加禁用硬中断,而硬中断不会被线程抢占,所以硬中断中只使用自旋锁就可以了。软中断对软中断,软中断中发生硬中断,硬中断返回时发现正在软中断中,不会再去执行软中断,只会排队软中断,所以软中断对软中断只使用自旋锁就可以了。软中断对硬中断,由于硬中断会抢占软中断,所以软中断中要禁用硬中断,硬中断中直接使用自旋锁就可以了。硬中断对硬中断,现在内核里已经禁止中断嵌套了,所以只使用自旋锁就可以了。
我们下面来看一下它们的接口与实现。
自旋锁并禁用软中断,软中断在这里就是下半部。
void spin_lock_bh(spinlock_t *lock)
void spin_unlock_bh(spinlock_t *lock)
实现如下,只分析加锁部分,解锁部分就不再分析了。
linux-src/include/linux/spinlock.h
inux-src/kernel/locking/spinlock.c
linux-src/include/linux/spinlock_api_smp.h
可以看到自旋锁的实现部分是一样的,只是加了一个禁用软中断的调用,禁用软中断本身也会禁用线程抢占,所以这里没有再去禁用抢占。
自旋锁并禁用硬中断,禁用软中断本身是带计数功能的,可以嵌套调用,但是禁用硬中断本身是没有计数的,不能嵌套调用,所以内核提供了两个版本,irq版lock会禁用中断,unlock会开启中断,irqsave版lock会禁用中断并保存现在的中断状态,unlock会恢复之前保存的中断状态。
void spin_lock_irq(spinlock_t *lock)
void spin_unlock_irq(spinlock_t *lock)
void spin_lock_irqsave(lock, flags)
void spin_unlock_irqsave(lock, flags)
实现如下,只分析加锁部分,解锁部分就不再分析了。
spin_lock_irq
linux-src/include/linux/spinlock.h
linux-src/kernel/locking/spinlock.c
linux-src/include/linux/spinlock_api_smp.h
spin_lock_irqsave
linux-src/include/linux/spinlock.h
linux-src/kernel/locking/spinlock.c
linux-src/include/linux/spinlock_api_smp.h
linux-src/include/linux/spinlock.h
可以看到自旋锁的实现部分是一样的,只是加了一个禁用硬中断和禁止抢占的调用。
6.3 raw_spin_lock的使用问题
可能很多人在看到内核代码时会感到有些奇怪,为啥有些地方用的是spinlock_t,有些地方用的却是raw_spinlock_t?raw_spinlock_t不是spinlock_t的实现细节吗,我们不是应该只使用接口性的东西,而不要使用实现性的东西吗?再仔细看spinlock_t和raw_spinlock_t的实质逻辑,好像也没啥区别啊?要回答这个问题,我们就要先从一件事情谈起,RTLinux。什么是RTLinux,什么是实时性?实时性是指一个系统对外部事件响应的及时性。很多嵌入式系统的OS都是实时OS,它们可以快速地对外部事件进行响应。这倒不是因为它们有多厉害,而是因为嵌入式系统都比较简单,它们面临的环境比较简单,要做的事情也比较简单,所以能做到及时性。而Linux是一个通用操作系统内核,通用这个词就代表Linux要面临很多情况,处理很多问题,所以就很难做到及时性。做到及时性最根本的一点就是要及时处理中断,因为中断代表的就是外部事件。但是在Linux内核里,有很多需要同步的地方都会禁用中断,这就导致中断不能及时响应。Linux在处理中断的时候也会禁用中断,Linux在这方面已经想了很多办法来解决,比如尽可能地缩小中断处理程序,把事情尽量都放到软中断或者线程里面去做。当很多中断处理的事情都被放到线程中去执行了,我们又面临着另外一个问题,如何尽快地让这些线程去抢占CPU立马获得执行。当一个非常不紧急的线程正好执行到自旋锁的临界区时,我们的非常着急的中断处理线程想获得CPU却没有办法,因为自旋锁的临界区不能休眠也就是说不可抢占,我们只能干等着。因此把自旋锁变得可休眠就成为了提高Linux的实时性的重要方法。为此Ingo Molnar等人开发了一个项目RTLinux,专门来提高Linux的实时性。其中一个很重要的方法就是把自旋锁替换为可休眠锁。但是有些临界区是确实不能休眠的,那怎么办呢?这些临界区就用raw_spinlock_t,raw_spinlock_t还保持原来的自旋语义,不会休眠。到目前为止(内核版本5.15.28),RTLinux还没有合入标准内核,所以目前的标准内核里raw_spinlock_t和spinlock_t效果是一样的。但是大家在内核编程的时候还是要尽量使用spinlock_t,除非你的临界区真的不能休眠,才去使用raw_spinlock_t。
参考文献:
《Linux Kernel Development》
《Understanding the Linux Kernel》
《Professional Linux Kernel Architecture》
Tags:
很赞哦! ()
随机图文
Linux 中断所有知识点
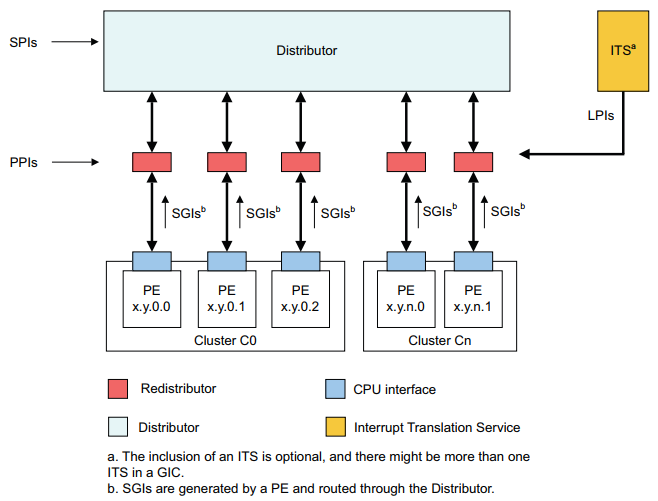
GIC,Generic Interrupt Controller。是ARM公司提供的一个通用的中断控制器。主要作用为:接受硬件中断信号,并经过一定处理后,分发给对应的CPU进行处理。 当前GIC 有四个版本,GIC v1~v4, 本文主要介绍GIC v3控制器。
深入理解CPU的调度原理
前言软件工程师们总习惯把OS(Operating System,操作系统)当成是一个非常值得信赖的管家,我们只管把程序托管到OS上运行,却很少深入了解操作系统的运行原理。确实,OS作为一个通用的
一文搞定 | Linux共享内存原理
在Linux系统中,每个进程都有独立的虚拟内存空间,也就是说不同的进程访问同一段虚拟内存地址所得到的数据是不一样的,这是因为不同进程相同的虚拟内存地址会映射到不同的物理内存地址上。 但有时候为了让不同进程之间进行通信,需要让不同进程共享相同的物理内存,Linux通过 共享内存 来实现这个功能。下面先来介绍一下Linux系统的共享内存的使用。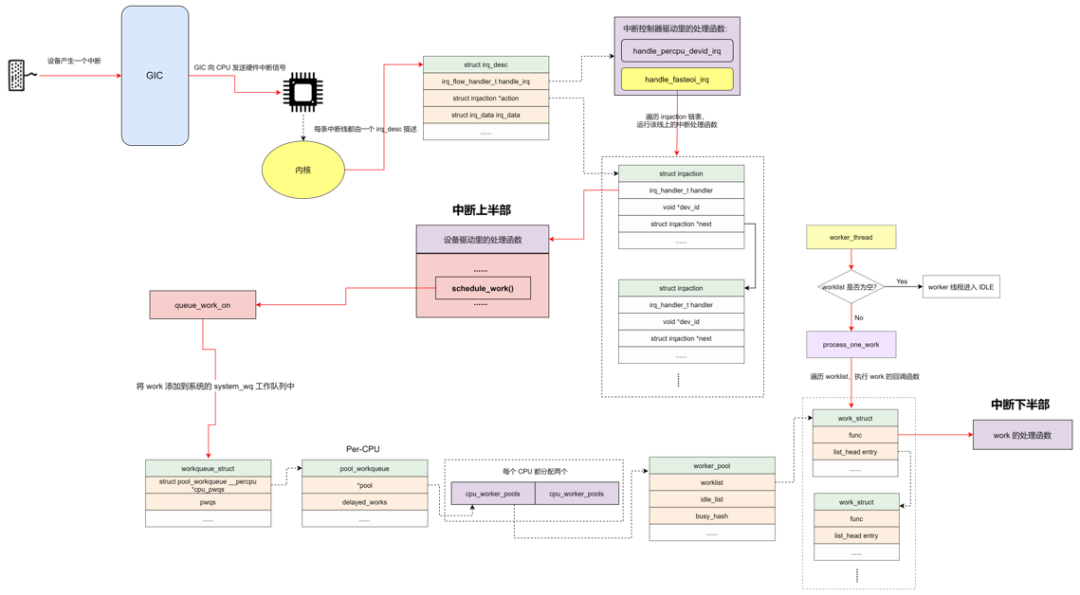
Linux 中断的底裤之 workqueue
workqueue 是除了 softirq 和 tasklet 以外最常用的下半部机制之一。workqueue 的本质是把 work 交给一个内核线程,在进程上下文调度的时候执行。因为这个特点,所以 workqueue 允许重新调度和睡眠,这种异步执行的进程上下文,能解决因为 softirq 和 tasklet 执行时间长而导致的系统实时性下降等问题。
文章评论
本站推荐

猜你喜欢

