您现在的位置是:首页 > 高性能编程高性能编程
linux c/c++最高效的计时方法
![]() 比目鱼2021-12-21【高性能编程】人已围观
比目鱼2021-12-21【高性能编程】人已围观
简介gettimeofday执行耗时约20ns一次(在最高缓存命中的情况下);
clock_gettime(CLOCK_MONOTONIC, pstTP),执行耗时约16.5ns一次(在最高缓存命中的情况下);
clock_gettime(CLOCK_MONOTONIC_RAW, pstTP),会系统调用进入内核,执行耗时约100ns起步;
直接从相应寄存器取,来自DPDK的套路,8ns搞定;
结论:
gettimeofday执行耗时约20ns一次(在最高缓存命中的情况下);
clock_gettime(CLOCK_MONOTONIC, pstTP),执行耗时约16.5ns一次(在最高缓存命中的情况下);
clock_gettime(CLOCK_MONOTONIC_RAW, pstTP),会系统调用进入内核,执行耗时约100ns起步;
直接从相应寄存器取,来自DPDK的套路,8ns搞定;
common.c
#include <sys/time.h>
#include <time.h>
#include <stdlib.h>
#include <stdio.h>
#include "common.h"
long long getustime(void)
{
struct timeval tv;
long long ust;
gettimeofday(&tv, NULL);
ust = ((long)tv.tv_sec)*1000000;
ust += tv.tv_usec;
return ust;
}
void getnstime(struct timespec *pstTP)
{
clock_gettime(CLOCK_MONOTONIC, pstTP);
return;
}
long diff_nstime(struct timespec *pstTP1, struct timespec *pstTP2)
{
return (pstTP2->tv_sec - pstTP1->tv_sec)*1000000000 + pstTP2->tv_nsec - pstTP1->tv_nsec;
}
inline long long rte_rdtsc(void)
{
union {
long long tsc_64;
struct {
unsigned int lo_32;
unsigned int hi_32;
};
} tsc;
asm volatile("rdtsc" :
"=a" (tsc.lo_32),
"=d" (tsc.hi_32));
return tsc.tsc_64;
}common.h
#ifndef COMMON_H_ #define COMMON_H_ #define ERROR_SUCCESS 0 #define ERROR_FAIL 1 #define IN #define OUT #define INOUT #define CACHE_LINE 64 //#define HASHSIZE 1*1024 typedef unsigned long ulong_t; long long getustime(void); void getnstime(struct timespec *pstTP); long diff_nstime(struct timespec *pstTP1, struct timespec *pstTP2); inline long long rte_rdtsc(void); #endif
main.c
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#include <ctype.h>
#include <unistd.h>
#include <sys/types.h>
#include <time.h>
#define __USE_GNU
#include "common.h"
#define LOOPCNT 1000000
int main(int argc, char ** argv)
{
struct timespec stTP1, stTP2, stTP3;
long diff,diff2,diff3;
int i;
long long t1, t2, t3;
while(1)
{
t1 = getustime();
for(i = 0;i<LOOPCNT;i++)
getnstime(&stTP3); /* 调用clock_gettime(CLOCK_MONOTONIC, pstTP); */
t2 = getustime();
diff = t2 - t1;
t1 = getustime();
for(i = 0;i<LOOPCNT;i++) /* 调用gettimeofday(&tv, NULL); */
t3 = getustime();
t2 = getustime();
diff2 = t2 - t1;
t1 = rte_rdtsc();
for(i = 0;i<LOOPCNT;i++)
t3 = rte_rdtsc(); /* 直接从rdtsc寄存器取,注:这个是x86_64上的 */
t2 = rte_rdtsc();
diff3 = t2 - t1;
printf("diff :%ldus %ldus %ldus\n", diff, diff2, diff3/3000); /* 这里cpu主频是3GHz */
}
return 0;
}[baolj@hs-10-20-30-230 recordtime]$ gcc main_t2.c common.c [baolj@hs-10-20-30-230 recordtime]$ ./a.out /* 执行了 LOOPCNT 1000000 次 */ diff :16464us 19793us 8063us diff :16447us 19794us 8063us diff :16449us 19791us 8063us diff :16448us 19794us 8063us diff :16448us 19793us 8063us diff :16449us 19792us 8063us
gettimeofday执行耗时约20ns一次;
clock_gettime(CLOCK_MONOTONIC, pstTP),执行耗时约16.5ns一次;
从rdtsc寄存器取,执行耗时约8ns一次;
将CLOCK_MONOTONIC改成CLOCK_MONOTONIC_RAW测试下:
[baolj@hs-10-20-30-230 recordtime]$ ./a.out diff :98731us 19802us 8062us diff :98816us 19804us 8062us diff :98733us 19801us 8062us diff :99108us 19802us 8062us diff :98782us 19797us 8062us diff :98769us 19802us 8062us
clock_gettime(CLOCK_MONOTONIC_RAW, pstTP),执行耗时约99ns一次;
使用strace -c -p xxx_pid监控下是否有系统调用:
[baolj@hs-10-20-30-230 ~]$ ps -ef | grep a.out baolj 16501 9529 99 13:39 pts/1 00:00:06 ./a.out baolj 16505 15694 0 13:39 pts/2 00:00:00 grep --color=auto a.out [baolj@hs-10-20-30-230 ~]$ strace -c -p 16501 strace: Process 16501 attached ^Cstrace: Process 16501 detached % time seconds usecs/call calls errors syscall ------ ----------- ----------- --------- --------- ---------------- 100.00 2.413938 2 1605112 clock_gettime 0.00 0.000000 0 1 write ------ ----------- ----------- --------- --------- ---------------- 100.00 2.413938 1605113 total [baolj@hs-10-20-30-230 ~]$
可以看出有大量的syscall clock_gettime
说明clock_gettime(CLOCK_MONOTONIC_RAW, pstTP)在当前环境下会syscall进内核;
总结下:
时钟这个值,无非就是有专门时钟器件在不停的滴答,每滴答一次刷相应的寄存器、同步到相应的内存(catche)中;
获取时间值的方式要么从对应的内存取,要么就从寄存器取;
gettimeofday 是从内存取,这就存在一个问题,这种内存通常是在内核才能访问的,如果gettimeofday系统调用进内核就蛋疼了(系统调用本身就开销大),后来linux整出来了一种机制VDSO(Virtual Dynamically-linked Shared Object),直白点就是直接把填时钟的内存映射到用户态,这样就是直接访存没有系统调用了;
clock_gettime(CLOCK_MONOTONIC, pstTP)跟gettimeofday比是半斤八两;
clock_gettime(CLOCK_MONOTONIC_RAW, pstTP)由于跟NTP(网络时钟同步协议)扯上关系了,得进内核取耗时就长了;
rdtsc寄存器从机器上电以来每个时钟周期加1次;
由于我们平常代码中计时,并不像上面main函数里面的代码,一个循环使劲搞cache命中几乎100%,使用gettimeofday/clock_gettime(CLOCK_MONOTONIC, pstTP)当cache不命中时,就不是上面执行出来的20ns 16.5ns一次了,就是真正的访问内存,估计就是50-60ns的样子;
clock_gettime(CLOCK_MONOTONIC_RAW, pstTP)就更恶劣了;最优秀的当然是直接从寄存器取了(寄存器访问速度0.3-0.5ns一次),直接,不存在缓存命中不命中的事,实测8ns搞定,这个套路来自DPDK;
-----------------------------
arm64,以华为鲲鹏920为例:
long long rte_rdtsc(void)
{
long long val;
int Current_Speed = 2600;
int External_Clock = 100;
asm volatile("mrs %0, CNTVCT_EL0" : "=r" (val));
return val*(Current_Speed/External_Clock);
}Tags:
很赞哦! ()
随机图文
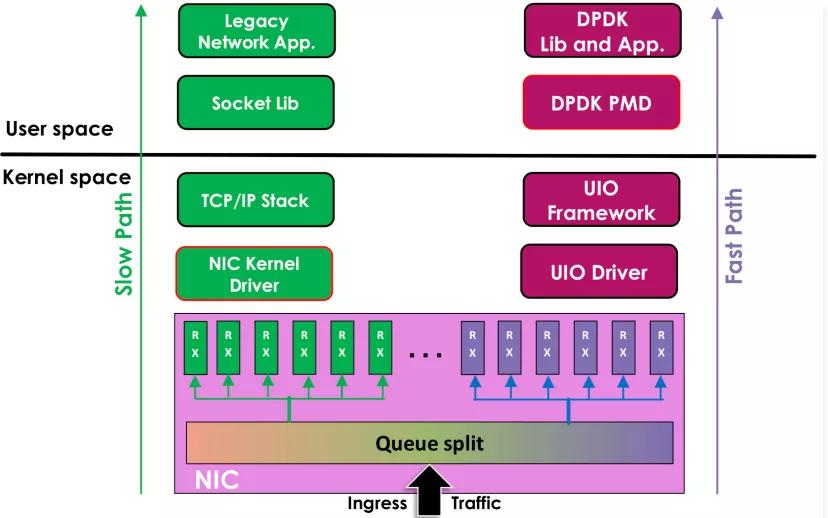
深入理解DPDK程序设计|Linux网络2.0
移动互联网不断发展,网络流量徒增,推动着网络技术不断地发展,而CPU的运行频率基本停留在10年前的水平,为了迎接超高速网络技术的挑战,软件也需要大幅度创新,结合硬件技术的发展,DPDK,一个以软件优化为主的数据面技术应时而生,它为今天NFV技术的发展提供了绝佳的平台可行性。 作为技术人员,我们可以从中DPDK学习大量的高性能编程技巧和代码优化技巧,包括高性能软件架构最佳实践、高效数据结构设计和内存优化技巧、应用程序性能分析以及网络性能优化的技巧。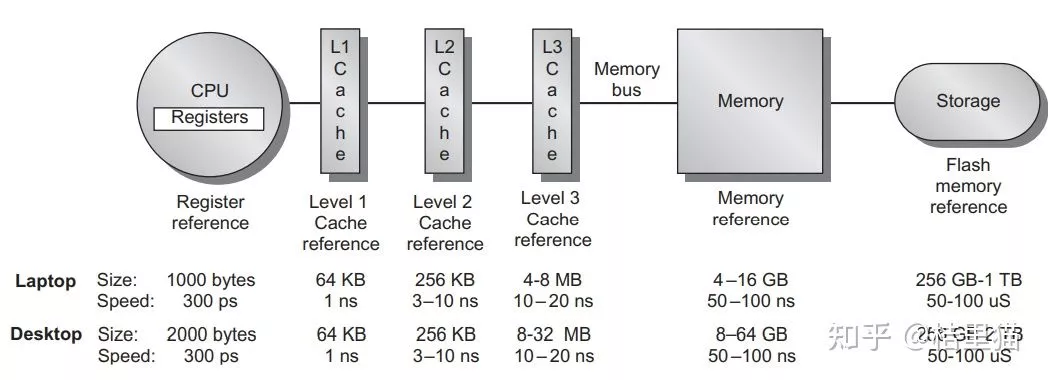
深入理解 Cache 工作原理
大家好,今天给大家分享一篇关于 Cache 的硬核的技术文,基本上关于Cache的所有知识点都可以在这篇文章里看到。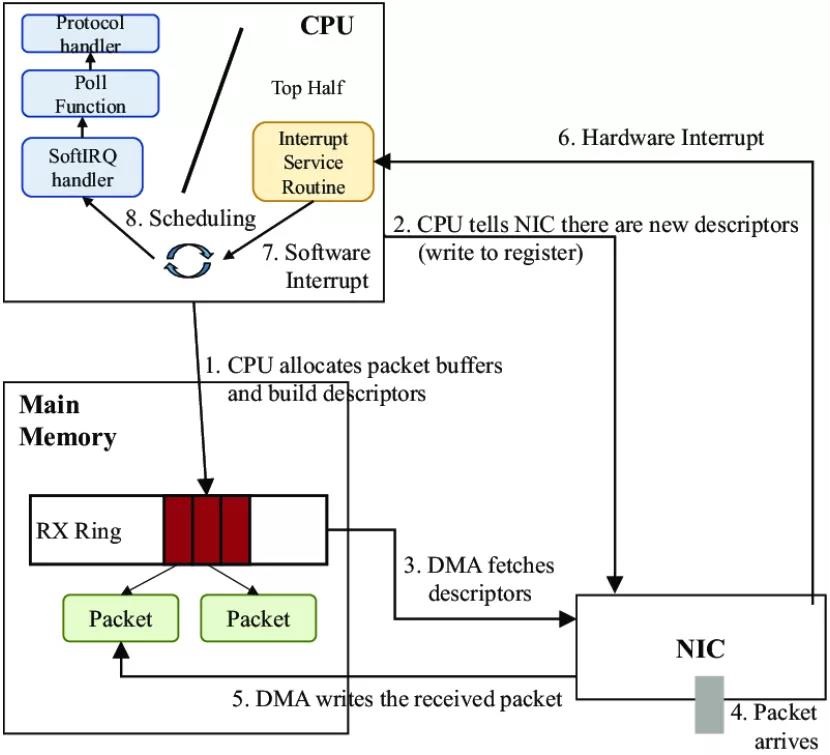
linux中报文从网卡到用户态recv的架子
分享一篇后台服务器性能优化之网络性能优化,希望大家对Linux网络有更深的理解。曾几何时,一切都是那么简单。网卡很慢,只有一个队列。当数据包到达时,网卡通过DMA复制数据包并发
文章评论
本站推荐

猜你喜欢

